- 天翼智库
- 2025年7月25日 08:57
OpenAI7月17日发布ChatGPT Agent,对Operator和Deep Research进行端到端训练整合,以适应网络信息研究与预定下单兼顾类的任务场景,这也与Manus、Genspark、Comet等初创公司形成直接竞争。从实测案例与行业反应来看,ChatGPT Agent未表现出明显优势,却遭到了Manus、Genspark们的对标硬刚,成为衬托后者差异化优势的背景板。通过这些对比,我们也看到背后Agent发展的路线之争,以及模型大厂与Agent应用企业各自究竟应该扮演什么角色,占据什么生态位。
ChatGPT Agent是目前核心功能最全的网页操作与信息研究类Agent
一是ChatGPT Agent属于端到端强化学习训练的Agent模型,与o3同系列。不同于manus、Genspark等用预设的工作流和程序引导模型完成任务,ChatGPT Agent将搜索、网页操作等工具调用与环境交互能力内化到模型本身,理论上自主规划、搜索与纠错能力更好。
表1:主要网页操作与信息研究类Agent核心功能对比
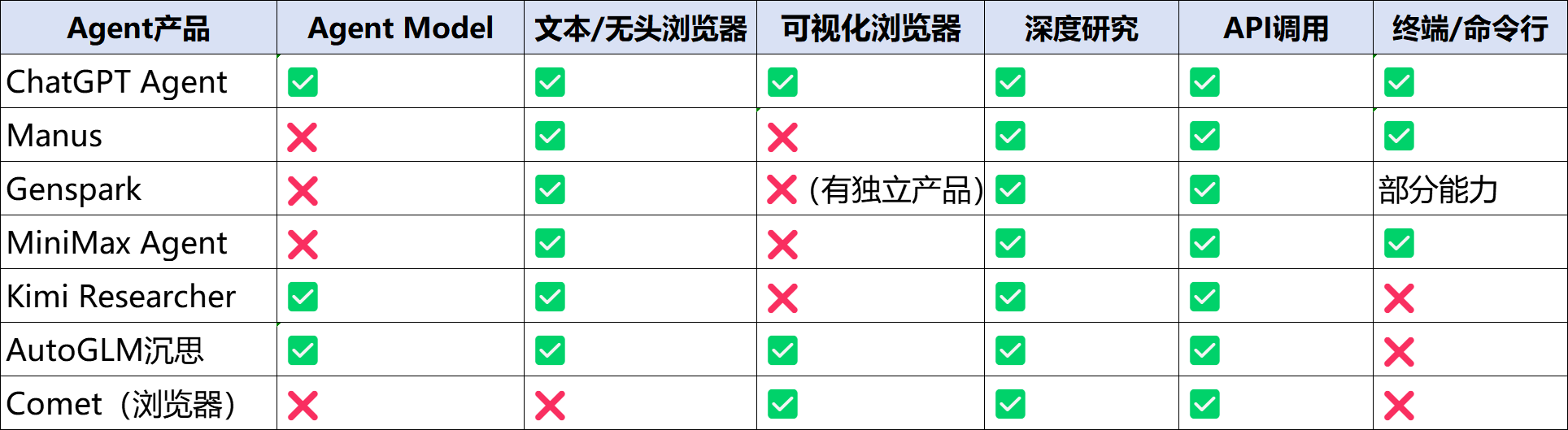
(根据实测和网络信息整理)
二是ChatGPT Agent 融合 Deep Research 和 Operator 两大产品。Operator 能够在网页上滚动、点击和输入文本,Deep Research则擅长分析和总结信息。整合源于OpenAI发现用户通过 Operator 的许多查询实际上需要深入研究,比如餐厅预订需要先做信息研究等。在同类Agent中,只有智谱AutoGLM沉思做了类似整合,但实测更接近于ChatGPT的Operator功能。
三是ChatGPT Agent 网络工具与终端工具比较完备。推理型用文本浏览器,网页操作用可视化浏览器、图像生成API补充可视化内容生成,以及直接 API 访问能力等。模型经过训练,可自主、灵活地选择合适的工具组合。 同时,ChatGPT Agent 在官方虚拟云电脑内给用户一个真实 Linux Shell,能直接运行代码、数据分析、调用API、接入Google Drive、GitHub等外部数据等。目前只有 Manus AI相对可比, Genspark 、Comet等终端能力有限或不具备。
ChatGPT Agent基准测试爆表但实测未表现明显优势,是一次稳健而平淡的更新
从OpenAI发布的报告看,ChatGPT Agent在结构化学术问题推理、数据分析、网页交互和电子表格四大维度上对o3有较大程度的领先。如在“人类的最后考试”(Humanity’s Last Exam)评估中,ChatGPT Agent正确率41.6%,是o3无工具模式的两倍(20.3%)。在DSBench测试中,ChatGPT Agent数据分析任务准确率87.9%(o3为64.1%),数据建模任务准确率85.5%(o3为77.1%)。在WebArena网页交互测试中,ChatGPT Agent准确率65.4%,超越o3,接近人类水平(78.2%)。在SpreadsheetBench测试中,ChatGPT Agent直接访问.xlsx文件准确率45.5%,优于Copilot in Excel(20%)。
但在同类产品实测中,ChatGPT Agent没有表现出明显优势。ChatGPT Agent发布后,Manus快速回应,发布10个实测对标案例,通过财务建模、生活规划、行程安排、消费购物、航班筛选等不同场景任务,证明ChatGPT Agent更多聚焦于基础信息检索和文本型交付,Manus在可视化呈现、跨平台操作和交付形式展示了自身优势。 Genspark反馈他们用同样的提示词,Genspark 的响应时间更短、成本更低,生成结果的质量也“高出好几倍”。从《OpenAI Agent测试报告》12个案例看(见表2),ChatGPT Agent的成功率、耗时都不是最优的,其中Genspark的确成功率最高、花费时间较少,AI浏览器Comet用时更是低一个数量级。
表2:《OpenAI Agent测试报告》测试小结
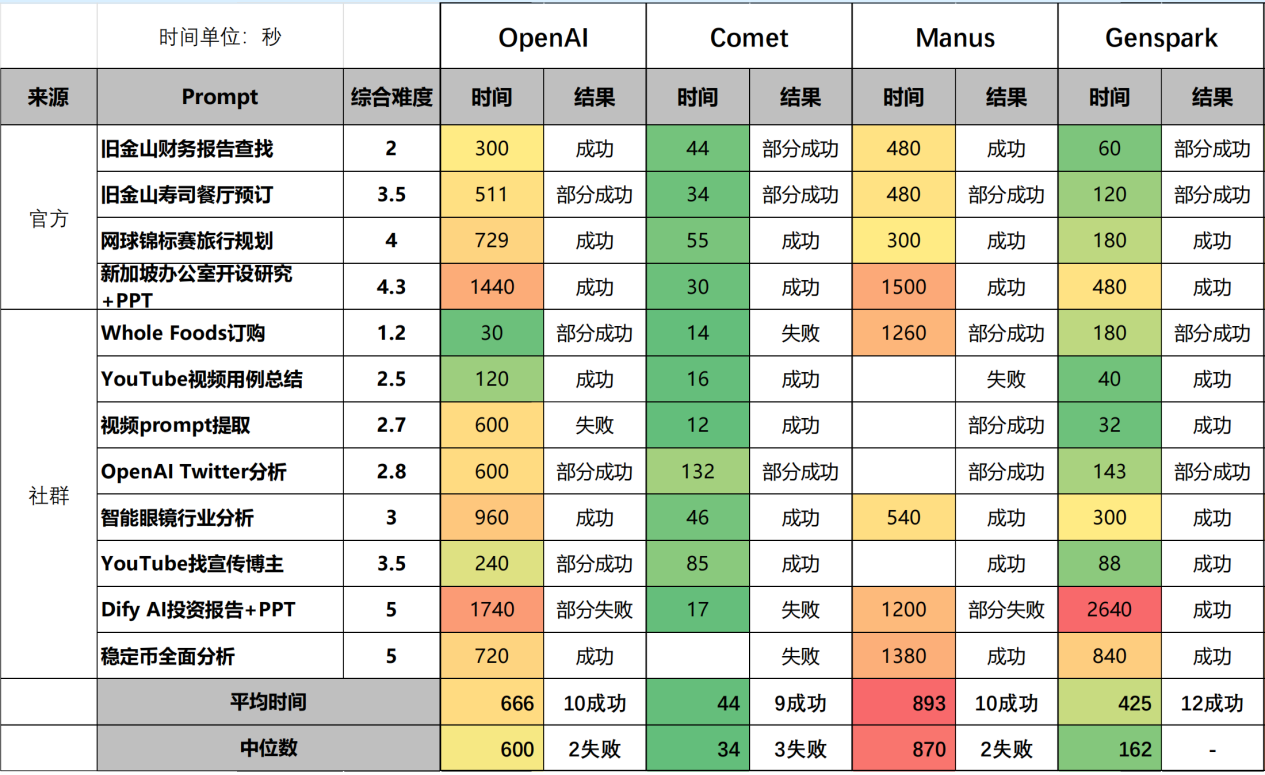
注:来源公众号郎瀚威will
分析其中的核心原因,一是ChatGPT Agent本身还处于早期阶段,产品打磨不如Manus等完善。如任务拆解复杂导致费时成本高、生成PPT细节处理粗糙等。Manus、Genspark应该是针对相关场景(如策划、调研等)预先做了场景搜索提示工程、结果整理逻辑、用户界面设计等优化。二是网页信息研究类Agent基础技术相对成熟、技术路径收敛,常规任务难以拉开差距。LLM+多工具整合+虚拟环境+对话式交互成为行业标准模式,各家基准测试都比较出色。三是网络信息深度研究场景的结果可验证性较弱,任务成功与完成度判断有一定的主观性,不能充分体现OpenAI Deep Reserach的能力。而在预定、订购类等可验证的网页操作场景,各家结果又普遍欠佳。
背后值得关注的Agent发展与竞争趋势
一是Agent Model与manus类Agent将长期并行。ChatGPT Agent 在网络信息处理场景暂时未表现出明显优势,但模型即产品是Agent的重要方向之一。Anthropic Claude实际是Coding类 Agent Model,模型大厂预计会聚焦高级数据分析、复杂决策、科学研究等通用又需从模型架构层面优化的场景,开展Agent Model训练。同时在领域收敛、数据积累较多的金融、电商、医疗等垂直场景也能产生超级Agent Model。Manus 类 Agent 模式依赖人类预设的工作流、上下文工程、多模型封装,以及特定场景的针对性优化,优点是可解释、可调试、易落地,更适合在不太复杂的信息搜索整理、标准业务流程智能化,以及强依赖场景know-how的具体场景落地。
二是“通用”Agent与浏览器Agent面临正面交锋。目前两者都是网络信息处理类Agent,理论上浏览器Agent更适合轻量级任务,Manus 和 Genspark 类更能处理复杂的跨平台任务。但从《OpenAI Agent测试报告》看,Perplexity 7月推出的AI浏览器Comet执行同类任务速度极快,成功率只是略低于“通用类”Agent。从访问量看,浏览器Agent代表Dia、Fellou与Manus相差一个量级,但增速很快。这不仅仅是要挑战Chrome等传统浏览器的地位,也将不可避免地与“通用”Agent形成遭遇战。作为网页信息交互的第一入口,浏览器具备一定的身位优势。
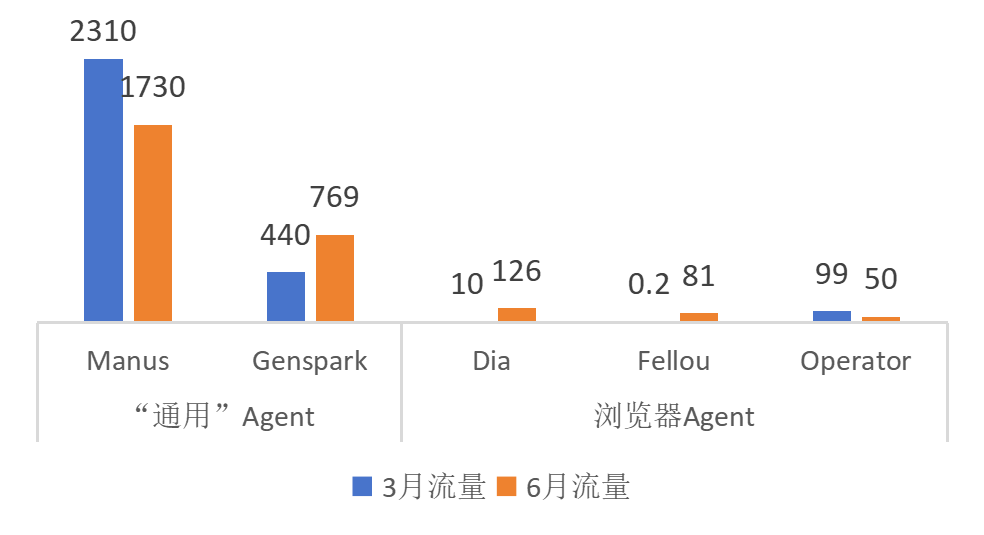
图1:典型“通用”Agent与浏览器Agent访问量比较
数据来源:similarweb;单位:万访问量
三是模型大厂与Agent应用企业需要明确各自的产业生态位。模型大厂更适合聚焦模型能力提升,搭平台、建生态。如Anthropic Claude积极开放API且行业调用量最高,推出模型上下文协议(MCP),快速形成开发与工具生态;谷歌发布Agent2Agent (A2A)协议,联手Salesforce等多家企业和大量开发者,构建企业Agent应用开发生态。微软、IBM等IT应用巨头推出企业级Agent应用开发/运维平台;Manus、Genspark、flowith等Agent初创企业不断涌现。OpenAI战略则显得较为模糊,API开放度不够,GPT Store未有明显起色,下场做Agent应用,实际落入与众多“Manus”竞争的局面,行业反馈平平。
在国内,MiniMax Agent、Kimi-K2、 夸克 AI 浏览器等也形成一定亮点,但受制于资本、模型能力等因素,海外Agent公司实际占据了流量的主导地位。国内公司可把握端到端强化学习模型与Manus类开发模式成为重要落地形态的趋势,重点开展垂直场景专属Agent训练打造,同步建设优质的Agent发展生态。













